Object detection boxes
Contents
Object detection boxes#
You shouldn’t set up limits in boundless openness, but if you set up limitlessness as boundless openness, you’ve trapped yourself
Boxes are quick to draw ✏️, but finicky to train a neural network with. This time, we’ll show you a geospatial object detection 🕵️ problem, where the objects are defined by a bounding box 🔲 with a specific class. By the end of this lesson, you should be able to:
Read OGR supported vector files and obtain the bounding boxes 🟨 of each geometry
Convert bounding boxes from geographic coordinates to 🖼️ image coordinates while clipping to the image extent
Use an affine transform to convert boxes in image coordinates to 🌐 geographic coordinates
🔗 Links:
🎉 Getting started#
These are the tools 🛠️ you’ll need.
import contextily
import numpy as np
import geopandas as gpd
import matplotlib.patches
import matplotlib.pyplot as plt
import pandas as pd
import planetary_computer
import pystac_client
import rioxarray
import shapely.affinity
import shapely.geometry
import torch
import torchdata
import xarray as xr
import zen3geo
0️⃣ Find high-resolution imagery and building footprints 🌇#
Let’s take a look at buildings over
Kampong Ayer, Brunei 🇧🇳! We’ll
use contextily.bounds2img() to get some 4-band RGBA
🌈 optical imagery
in a numpy.ndarray format.
image, extent = contextily.bounds2img(
w=114.94,
s=4.88,
e=114.95,
n=4.89,
ll=True,
source=contextily.providers.Esri.WorldImagery,
)
print(f"Spatial extent in EPSG:3857: {extent}")
print(f"Image dimensions (height, width, channels): {image.shape}")
Spatial extent in EPSG:3857: (12794947.038712224, 12796475.779277924, 543620.1451641723, 545148.8857298762)
Image dimensions (height, width, channels): (1280, 1280, 4)
This is how Brunei’s 🚣 Venice of the East looks like from above.
fig, ax = plt.subplots(nrows=1, figsize=(9, 9))
plt.imshow(X=image, extent=extent)
<matplotlib.image.AxesImage at 0x7efe32194d90>

Tip
For more raster basemaps, check out:
Georeference image using rioxarray 🌐#
To enable slicing 🔪 with xbatcher later, we’ll need to turn the
numpy.ndarray image 🖼️ into an xarray.DataArray grid
with coordinates 🖼️. If you already have a georeferenced grid (e.g. from
zen3geo.datapipes.RioXarrayReader), this step can be skipped ⏭️.
# Turn RGBA image from channel-last to channel-first and get 3-band RGB only
_image = image.transpose(2, 0, 1) # Change image from (H, W, C) to (C, H, W)
rgb_image = _image[0:3, :, :] # Get just RGB by dropping RGBA's alpha channel
print(f"RGB image shape: {rgb_image.shape}")
RGB image shape: (3, 1280, 1280)
Georeferencing is done by putting the 🚦 RGB image into an
xarray.DataArray object with (band, y, x) coordinates, and then
setting a coordinate reference system 📐 using
rioxarray.rioxarray.XRasterBase.set_crs().
left, right, bottom, top = extent # xmin, xmax, ymin, ymax
dataarray = xr.DataArray(
data=rgb_image,
coords=dict(
band=[0, 1, 2], # Red, Green, Blue
y=np.linspace(start=top, stop=bottom, num=rgb_image.shape[1]),
x=np.linspace(start=left, stop=right, num=rgb_image.shape[2]),
),
dims=("band", "y", "x"),
)
dataarray = dataarray.rio.write_crs(input_crs="EPSG:3857")
dataarray
<xarray.DataArray (band: 3, y: 1280, x: 1280)>
array([[[101, 74, 64, ..., 77, 42, 33],
[116, 107, 101, ..., 75, 57, 55],
[125, 133, 135, ..., 46, 37, 37],
...,
[169, 169, 169, ..., 50, 59, 42],
[167, 167, 167, ..., 48, 66, 74],
[166, 166, 166, ..., 46, 56, 79]],
[[ 97, 70, 60, ..., 105, 70, 61],
[112, 103, 97, ..., 103, 85, 83],
[121, 129, 131, ..., 72, 63, 63],
...,
[164, 164, 164, ..., 71, 81, 64],
[161, 161, 161, ..., 69, 88, 96],
[160, 160, 160, ..., 65, 76, 99]],
[[ 86, 59, 49, ..., 80, 45, 36],
[101, 92, 86, ..., 78, 60, 58],
[110, 118, 120, ..., 47, 38, 38],
...,
[142, 142, 142, ..., 38, 45, 28],
[139, 139, 139, ..., 36, 52, 60],
[138, 138, 138, ..., 33, 41, 64]]], dtype=uint8)
Coordinates:
* band (band) int64 0 1 2
* y (y) float64 5.451e+05 5.451e+05 ... 5.436e+05 5.436e+05
* x (x) float64 1.279e+07 1.279e+07 1.279e+07 ... 1.28e+07 1.28e+07
spatial_ref int64 0Load cloud-native vector files 💠#
Now to pull in some building footprints 🛖. Let’s make a STAC API query to get a GeoParquet file (a cloud-native columnar 🀤 geospatial vector file format) over our study area.
catalog = pystac_client.Client.open(
url="https://planetarycomputer.microsoft.com/api/stac/v1"
)
items = catalog.search(
collections=["ms-buildings"], query={"msbuildings:region": {"eq": "Brunei"}}
)
item = next(items.get_items())
item
Item: Brunei_2022-07-06
| ID: Brunei_2022-07-06 |
| Bounding Box: [114.07468103, 4.01156914, 115.32106269, 5.04331691] |
| Datetime: 2022-07-06 00:00:00+00:00 |
| title: Building footprints |
| datetime: 2022-07-06T00:00:00Z |
| description: Parquet dataset with the building footprints |
| table:columns: [{'name': 'geometry', 'type': 'byte_array', 'description': 'Building footprint polygons'}] |
| table:row_count: 141279 |
| msbuildings:region: Brunei |
| stac_extensions: ['https://stac-extensions.github.io/table/v1.2.0/schema.json'] |
STAC Extensions
| https://stac-extensions.github.io/table/v1.2.0/schema.json |
Assets
Asset: Building Footprints
| href: abfs://footprints/global/2022-07-06/ml-buildings.parquet/RegionName=Brunei |
| Title: Building Footprints |
| Description: Parquet dataset with the building footprints for this region. |
| Media type: application/x-parquet |
| Roles: ['data'] |
| Owner: |
| table:storage_options: {'account_name': 'bingmlbuildings'} |
Links
Link:
| Rel: collection |
| Target: https://planetarycomputer.microsoft.com/api/stac/v1/collections/ms-buildings |
| Media Type: application/json |
Link:
| Rel: parent |
| Target: https://planetarycomputer.microsoft.com/api/stac/v1/collections/ms-buildings |
| Media Type: application/json |
Link:
Microsoft Planetary Computer STAC API
| Rel: root |
| Target: |
| Media Type: application/json |
Link:
| Rel: self |
| Target: https://planetarycomputer.microsoft.com/api/stac/v1/collections/ms-buildings/items/Brunei_2022-07-06 |
| Media Type: application/geo+json |
Next, we’ll sign 🔏 the URL to the STAC Item Asset, and load ⤵️ the GeoParquet
file using geopandas.read_parquet().
asset = planetary_computer.sign(item.assets["data"])
geodataframe = gpd.read_parquet(
path=asset.href, storage_options=asset.extra_fields["table:storage_options"]
)
geodataframe
| geometry | quadkey | |
|---|---|---|
| 0 | POLYGON ((114.94827 4.94591, 114.94823 4.94586... | 132322011 |
| 1 | POLYGON ((115.05357 5.03283, 115.05349 5.03285... | 132322011 |
| 2 | POLYGON ((115.05879 5.02164, 115.05849 5.02175... | 132322011 |
| 3 | POLYGON ((114.92007 4.95328, 114.91992 4.95335... | 132322011 |
| 4 | POLYGON ((114.93861 4.92956, 114.93870 4.92955... | 132322011 |
| ... | ... | ... |
| 141274 | POLYGON ((114.71998 4.15331, 114.71997 4.15333... | 132322031 |
| 141275 | POLYGON ((114.63725 4.01162, 114.63720 4.01167... | 132322031 |
| 141276 | POLYGON ((114.69539 4.19415, 114.69537 4.19420... | 132322031 |
| 141277 | POLYGON ((114.62846 4.05323, 114.62844 4.05327... | 132322031 |
| 141278 | POLYGON ((115.32106 4.32911, 115.32106 4.32914... | 132322102 |
141279 rows × 2 columns
This geopandas.GeoDataFrame contains building outlines across
Brunei 🇧🇳. Let’s do a spatial subset ✂️ to just the Kampong Ayer study area
using geopandas.GeoDataFrame.cx, and reproject it using
geopandas.GeoDataFrame.to_crs() to match the coordinate reference
system of the optical image.
_gdf_kpgayer = geodataframe.cx[114.94:114.95, 4.88:4.89]
gdf_kpgayer = _gdf_kpgayer.to_crs(crs="EPSG:3857")
gdf_kpgayer
| geometry | quadkey | |
|---|---|---|
| 75265 | POLYGON ((12795718.325 544086.389, 12795729.66... | 132322013 |
| 75266 | POLYGON ((12795564.840 544661.874, 12795568.21... | 132322013 |
| 75464 | POLYGON ((12795409.113 544204.734, 12795410.13... | 132322013 |
| 75572 | POLYGON ((12795542.673 544277.711, 12795543.76... | 132322013 |
| 75595 | POLYGON ((12795578.547 543955.222, 12795599.91... | 132322013 |
| ... | ... | ... |
| 140596 | POLYGON ((12795242.965 544192.243, 12795254.87... | 132322013 |
| 140645 | POLYGON ((12795912.384 544327.305, 12795914.98... | 132322013 |
| 141034 | POLYGON ((12795791.083 544062.615, 12795781.29... | 132322013 |
| 141048 | POLYGON ((12795253.585 544036.445, 12795260.67... | 132322013 |
| 141228 | POLYGON ((12795260.339 544632.328, 12795273.33... | 132322013 |
612 rows × 2 columns
Preview 👀 the building footprints to check that things are in the right place.
ax = gdf_kpgayer.plot(figsize=(9, 9))
contextily.add_basemap(
ax=ax,
source=contextily.providers.Stamen.TonerLite,
crs=gdf_kpgayer.crs.to_string(),
)
ax
<AxesSubplot:>
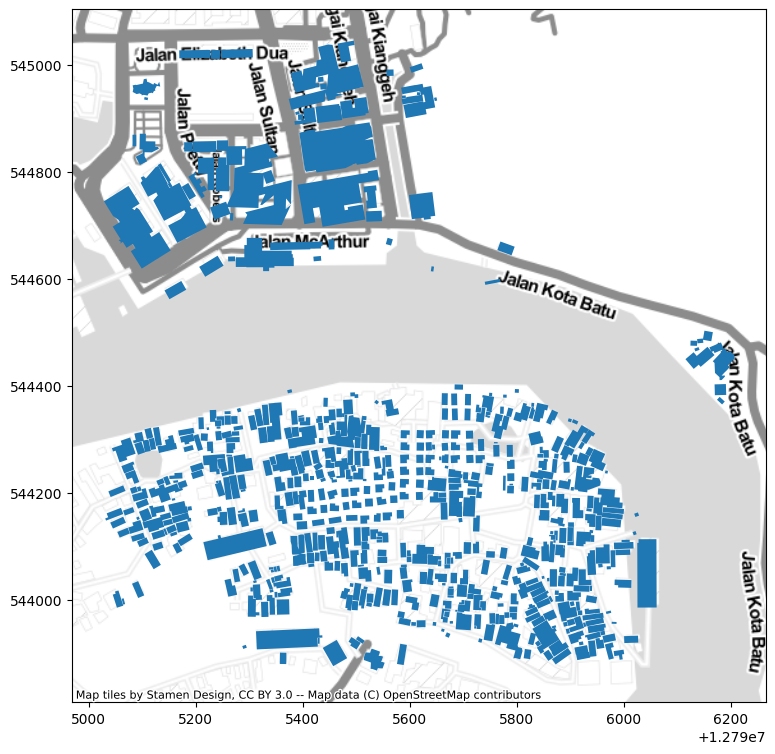
Hmm, seems like the Stamen basemap doesn’t know that some of the buildings are on water 😂.
1️⃣ Pair image chips with bounding boxes 🧑🤝🧑#
Here comes the fun 🛝 part! This section is all about generating 128x128 chips 🫶 paired with bounding boxes. Let’s go 🚲!
Create 128x128 raster chips and clip vector geometries with it ✂️#
From the large 1280x1280 scene 🖽️, we will first slice out a hundred 128x128
chips 🍕 using zen3geo.datapipes.XbatcherSlicer (functional name:
slice_with_xbatcher).
dp_raster = torchdata.datapipes.iter.IterableWrapper(iterable=[dataarray])
dp_xbatcher = dp_raster.slice_with_xbatcher(input_dims={"y": 128, "x": 128})
dp_xbatcher
XbatcherSlicerIterDataPipe
For each 128x128 chip 🍕, we’ll then find the vector geometries 🌙 that fit
within the chip’s spatial extent. This will be 🤸 done using
zen3geo.datapipes.GeoPandasRectangleClipper (functional name:
clip_vector_with_rectangle).
dp_vector = torchdata.datapipes.iter.IterableWrapper(iterable=[gdf_kpgayer])
dp_clipped = dp_vector.clip_vector_with_rectangle(mask_datapipe=dp_xbatcher)
dp_clipped
GeoPandasRectangleClipperIterDataPipe
Important
When using zen3geo.datapipes.GeoPandasRectangleClipper 💇, there
should only be one ‘global’ 🌐 vector geopandas.GeoSeries or
geopandas.GeoDataFrame.
If your raster DataPipe has chips 🍕 with different coordinate reference
systems (e.g. multiple UTM Zones 🌏🌍🌎),
zen3geo.datapipes.GeoPandasRectangleClipper will actually reproject
🔄 the ‘global’ vector to the coordinate reference system of each chip, and
clip ✂️ the geometries accordingly to the chip’s bounding box extent 😎.
This dp_clipped DataPipe will yield 🤲 a tuple of (vector, raster)
objects for each 128x128 chip. Let’s inspect 🧐 one to see how they look like.
# Get one chip with over 10 building footprint geometries
for vector, raster in dp_clipped:
if len(vector) > 10:
break
These are the spatially subsetted vector geometries 🌙 in one 128x128 chip.
vector
| geometry | quadkey | |
|---|---|---|
| 136629 | POLYGON ((12795226.452 544733.061, 12795252.42... | 132322013 |
| 104134 | POLYGON ((12795099.435 544690.503, 12795099.43... | 132322013 |
| 85553 | POLYGON ((12795099.435 544773.939, 12795099.43... | 132322013 |
| 88189 | POLYGON ((12795173.325 544771.647, 12795187.78... | 132322013 |
| 111809 | POLYGON ((12795185.931 544790.568, 12795210.50... | 132322013 |
| 115363 | POLYGON ((12795149.028 544777.963, 12795147.26... | 132322013 |
| 110664 | POLYGON ((12795203.830 544826.201, 12795204.11... | 132322013 |
| 99678 | POLYGON ((12795249.180 544754.879, 12795244.13... | 132322013 |
| 121817 | POLYGON ((12795237.069 544763.752, 12795237.50... | 132322013 |
| 131297 | POLYGON ((12795239.495 544843.496, 12795252.42... | 132322013 |
| 133040 | POLYGON ((12795099.435 544814.744, 12795099.43... | 132322013 |
| 129667 | POLYGON ((12795178.138 544843.496, 12795192.76... | 132322013 |
| 92301 | POLYGON ((12795193.512 544843.496, 12795238.29... | 132322013 |
This is the raster chip/mask 🤿 used to clip the vector.
raster
<xarray.Dataset>
Dimensions: (band: 3, y: 128, x: 128)
Coordinates:
* band (band) int64 0 1 2
* y (y) float64 5.448e+05 5.448e+05 ... 5.447e+05
* x (x) float64 1.28e+07 1.28e+07 ... 1.28e+07
spatial_ref int64 0
Data variables:
__xarray_dataarray_variable__ (band, y, x) uint8 154 171 143 ... 111 90 75And here’s a side by side visualization of the 🌈 RGB chip image (left) and 🔷 vector building footprint polygons (right).
fig, ax = plt.subplots(ncols=2, figsize=(18, 9), sharex=True, sharey=True)
raster.__xarray_dataarray_variable__.plot.imshow(ax=ax[0])
vector.plot(ax=ax[1])
<AxesSubplot:>
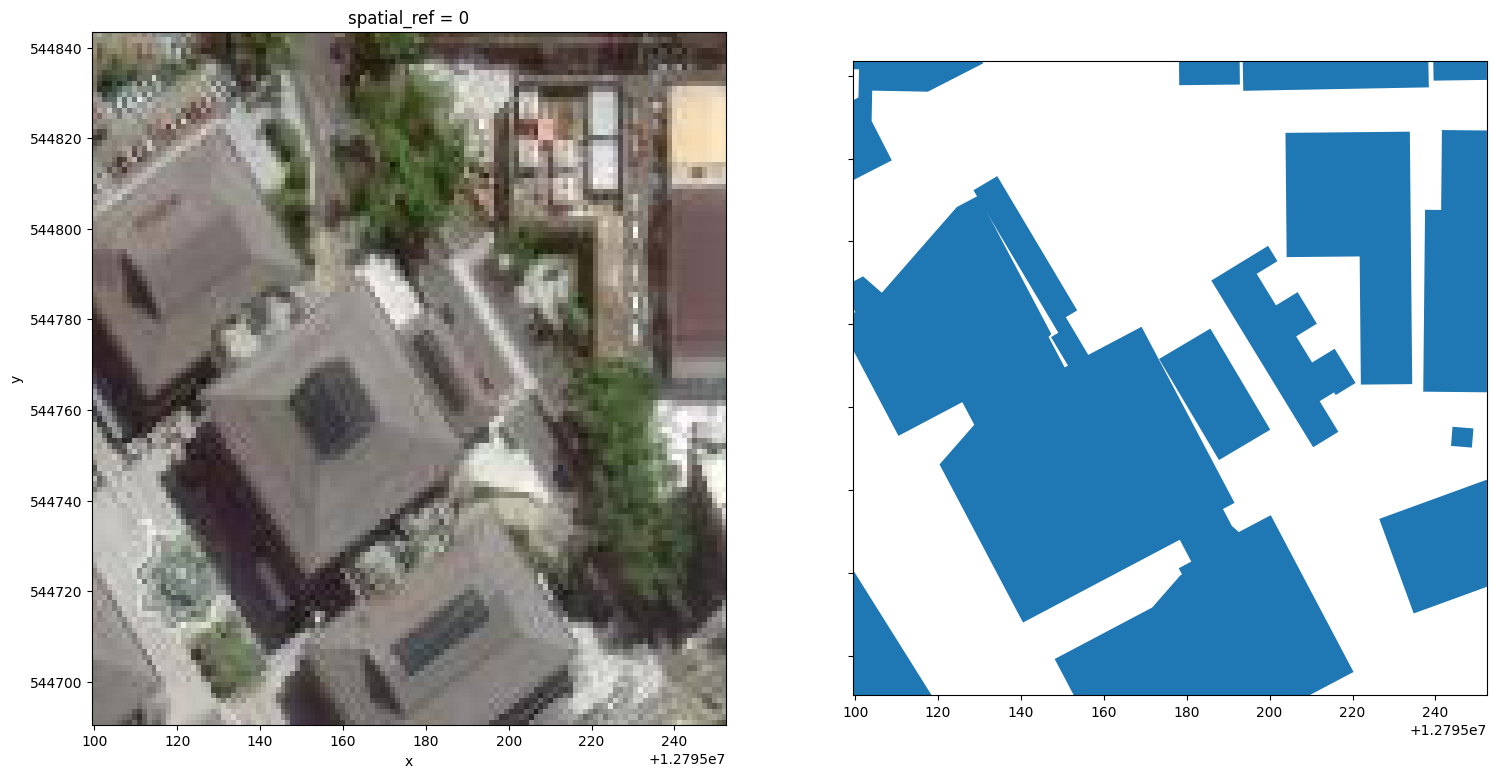
Cool, these buildings are part of the 🏬 Yayasan Shopping Complex in Bandar Seri Begawan 🌆. We can see that the raster image 🖼️ on the left aligns ok with the vector polygons 💠 on the right.
Note
The optical 🛰️ imagery shown here is not the imagery used to digitize the building footprints 🏢! This is an example tutorial using two different data sources, that we just so happened to have plotted in the same geographic space 😝.
From polygons in geographic coordinates to boxes in image coordinates ↕️#
Up to this point, we still have the actual 🛖 building footprint polygons. In this step 📶, we’ll convert these polygons into a format suitable for ‘basic’ object detection 🥅 models in computer vision. Specifically:
The polygons 🌙 (with multiple vertices) will be simplified to a horizontal bounding box 🔲 with 4 corner vertices only.
The 🌐 geographic coordinates of the box which use lower left corner and upper right corner (i.e. y increases from South to North ⬆️) will be converted to 🖼️ image coordinates (0-128) which use the top left corner and bottom right corner (i.e y increases from Top to Bottom ⬇️).
Let’s start by using geopandas.GeoSeries.bounds to get the
geographic bounds 🗺️ of each building footprint geometry 📐 in each 128x128
chip.
def polygon_to_bbox(geom_and_chip) -> (gpd.GeoDataFrame, xr.Dataset):
"""
Get bounding box (minx, miny, maxx, maxy) coordinates for each geometry in
a geopandas.GeoDataFrame.
(maxx,maxy)
ul-------ur
^ | |
| | geo | y increases going up, x increases going right
y | |
ll-------lr
(minx,miny) x-->
"""
gdf, chip = geom_and_chip
bounds: gpd.GeoDataFrame = gdf.bounds
assert tuple(bounds.columns) == ("minx", "miny", "maxx", "maxy")
return bounds, chip
dp_bbox = dp_clipped.map(fn=polygon_to_bbox)
Next, the geographic 🗺️ bounding box coordinates (in EPSG:3857) will be converted to image 🖼️ or pixel coordinates (0-128 scale). The y-direction will be flipped 🤸 upside down, and we’ll be using the spatial bounds (or corner coordinates) of the 128x128 image chip as a reference 📍.
def geobox_to_imgbox(bbox_and_chip) -> (pd.DataFrame, xr.Dataset):
"""
Convert bounding boxes in a pandas.DataFrame from geographic coordinates
(minx, miny, maxx, maxy) to image coordinates (x1, y1, x2, y2) based on the
spatial extent of a raster image chip.
(x1,y1)
ul-------ur
y | |
| | img | y increases going down, x increases going right
v | |
ll-------lr
x--> (x2,y2)
"""
geobox, chip = bbox_and_chip
x_res, y_res = chip.rio.resolution()
assert y_res < 0
left, bottom, right, top = chip.rio.bounds()
assert top > bottom
imgbox = pd.DataFrame()
imgbox["x1"] = (geobox.minx - left) / x_res # left
imgbox["y1"] = (top - geobox.maxy) / -y_res # top
imgbox["x2"] = (geobox.maxx - left) / x_res # right
imgbox["y2"] = (top - geobox.miny) / -y_res # bottom
assert all(imgbox.x2 > imgbox.x1)
assert all(imgbox.y2 > imgbox.y1)
return imgbox, chip
dp_ibox = dp_bbox.map(fn=geobox_to_imgbox)
Now to plot 🎨 and double check that the boxes are positioned correctly in 0-128 image space 🌌.
# Get one chip with over 10 building footprint geometries
for ibox, ichip in dp_ibox:
if len(ibox) > 10:
break
ibox
| x1 | y1 | x2 | y2 | |
|---|---|---|---|---|
| 136629 | 106.267600 | 84.477237 | 128.000000 | 111.487401 |
| 104134 | 0.000000 | 102.624007 | 15.915053 | 128.000000 |
| 85553 | 0.000000 | 27.158230 | 101.079502 | 128.000000 |
| 88189 | 61.819662 | 53.976790 | 84.270007 | 80.526231 |
| 111809 | 72.365741 | 37.279512 | 101.486711 | 77.930713 |
| 115363 | 24.359445 | 23.205062 | 47.607712 | 61.791212 |
| 110664 | 87.341014 | 14.232860 | 112.921057 | 65.286400 |
| 99678 | 120.748550 | 73.796988 | 125.282081 | 78.005132 |
| 121817 | 115.149687 | 13.901857 | 128.000000 | 66.843693 |
| 131297 | 117.179471 | 0.000000 | 128.000000 | 3.929291 |
| 133040 | 0.000000 | 0.000000 | 26.325074 | 24.055215 |
| 129667 | 65.845721 | 0.000000 | 78.135024 | 4.845090 |
| 92301 | 78.708163 | 0.000000 | 116.277647 | 5.983405 |
fig, ax = plt.subplots(ncols=2, figsize=(18, 9), sharex=True, sharey=True)
ax[0].imshow(X=ichip.__xarray_dataarray_variable__.transpose("y", "x", "band"))
for i, row in ibox.iterrows():
rectangle = matplotlib.patches.Rectangle(
xy=(row.x1, row.y1),
width=row.x2 - row.x1,
height=row.y2 - row.y1,
edgecolor="blue",
linewidth=1,
facecolor="none",
)
ax[1].add_patch(rectangle)
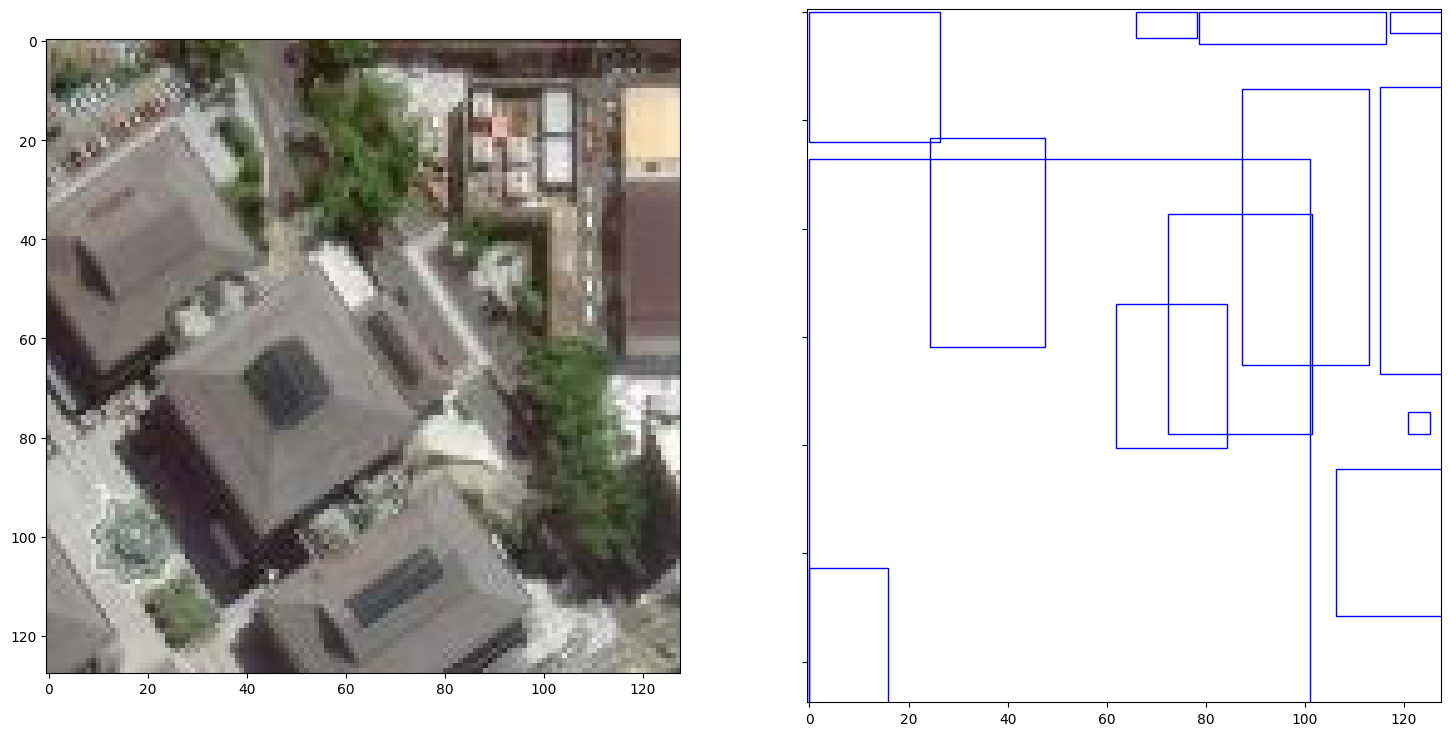
Cool, the 🟦 bounding boxes on the right subplot are correctly positioned 🧭 (compare it with the figure in the previous subsection).
Hint
Instead of a bounding box 🥡 object detection task, you can also use the building polygons 🏘️ for a segmentation task 🧑🎨 following Vector segmentation masks.
If you still prefer doing object detection 🕵️, but want a different box format
(see options in torchvision.ops.box_convert()),
like 🎌 centre-based coordinates with width and height (cxcywh), or
📨 oriented/rotated bounding box coordinates, feel free to implement your own
function and DataPipe for it 🤗!
2️⃣ There and back again 🧙#
What follows on from here requires focus 🤫. To start, we’ll pool the hundred
💯 128x128 chips into 10 batches (10 chips per batch) using
torchdata.datapipes.iter.Batcher (functional name: batch).
dp_batch = dp_ibox.batch(batch_size=10)
print(f"Number of items in first batch: {len(list(dp_batch)[0])}")
Number of items in first batch: 10
Batch boxes with variable lengths 📏#
Next, we’ll stack 🥞 all the image chips into a single tensor (recall
Chipping and batching data), and concatenate 📚 the bounding boxes into a list of
tensors using torchdata.datapipes.iter.Collator (functional name:
collate).
def boximg_collate_fn(samples) -> (list[torch.Tensor], torch.Tensor, list[dict]):
"""
Converts bounding boxes and raster images to tensor objects and keeps
geographic metadata (spatial extent, coordinate reference system and
spatial resolution).
Specifically, the bounding boxes in pandas.DataFrame format are each
converted to a torch.Tensor and collated into a list, while the raster
images in xarray.Dataset format are converted to a torch.Tensor (int16
dtype) and stacked into a single torch.Tensor.
"""
box_tensors: list[torch.Tensor] = [
torch.as_tensor(sample[0].to_numpy(dtype=np.float32)) for sample in samples
]
tensors: list[torch.Tensor] = [
torch.as_tensor(
data=sample[1]
.data_vars.get(key="__xarray_dataarray_variable__")
.data.astype("int16"),
)
for sample in samples
]
img_tensors = torch.stack(tensors=tensors)
metadata: list[dict] = [
{
"bbox": sample[1].rio.bounds(),
"crs": sample[1].rio.crs,
"resolution": sample[1].rio.resolution(),
}
for sample in samples
]
return box_tensors, img_tensors, metadata
dp_collate = dp_batch.collate(collate_fn=boximg_collate_fn)
print(f"Number of mini-batches: {len(list(dp_collate))}")
mini_batch_box, mini_batch_img, mini_batch_metadata = list(dp_collate)[1]
print(f"Mini-batch image tensor shape: {mini_batch_img.shape}")
print(f"Mini-batch box tensors: {mini_batch_box}")
print(f"Mini-batch metadata: {mini_batch_metadata}")
Number of mini-batches: 10
Mini-batch image tensor shape: torch.Size([10, 3, 128, 128])
Mini-batch box tensors: [tensor([[123.9093, 104.9202, 128.0000, 128.0000],
[112.9828, 106.5683, 118.8773, 124.6974],
[113.1629, 26.8098, 128.0000, 44.9749]]), tensor([[117.0043, 115.3977, 128.0000, 128.0000],
[ 0.0000, 104.9909, 26.1012, 128.0000],
[ 65.7458, 118.2312, 78.0862, 128.0000],
[ 78.5054, 116.4489, 116.1789, 128.0000],
[ 3.0884, 47.5740, 9.3976, 52.5646],
[ 0.0000, 18.7743, 28.4082, 45.3366]]), tensor([[117.9412, 100.7308, 128.0000, 128.0000],
[115.7629, 74.4706, 124.1512, 83.4432],
[ 36.1700, 119.8452, 74.3699, 128.0000],
[ 0.0000, 115.3069, 35.1435, 128.0000],
[110.2586, 65.3755, 128.0000, 91.0184],
[111.3105, 69.6327, 118.5406, 75.7000],
[101.3318, 3.0389, 128.0000, 67.6447]]), tensor([[ 0.0000, 87.2009, 106.9465, 128.0000],
[ 53.5764, 47.6009, 98.3723, 81.2635],
[126.2443, 4.6490, 128.0000, 14.6764],
[ 0.0000, 63.6644, 16.4110, 88.8571],
[ 15.2246, 58.3821, 56.9873, 88.2886],
[ 22.5505, 26.3118, 33.0069, 35.9500],
[ 13.6754, 25.8521, 21.1058, 32.7201],
[ 18.9505, 15.9668, 27.8914, 24.1055],
[ 0.0000, 0.0000, 90.5514, 61.9928]]), tensor([[ 0.0000, 4.4358, 9.4605, 14.6412],
[21.1518, 26.8578, 74.4305, 80.4817],
[21.9534, 43.8958, 55.8650, 59.0243],
[72.5806, 47.9954, 77.5368, 53.9594],
[22.3033, 45.0466, 28.6352, 49.5979],
[45.8440, 40.1061, 51.2531, 44.5580],
[34.4906, 0.0000, 55.9927, 9.6874]]), tensor([], size=(0, 4)), tensor([], size=(0, 4)), tensor([], size=(0, 4)), tensor([], size=(0, 4)), tensor([], size=(0, 4))]
Mini-batch metadata: [{'bbox': (12794946.441081041, 544843.4961954451, 12795099.434663847, 544996.4897782521), 'crs': CRS.from_epsg(3857), 'resolution': (1.1952623656738226, -1.1952623656793226)}, {'bbox': (12795099.434663849, 544843.4961954451, 12795252.428246655, 544996.4897782521), 'crs': CRS.from_epsg(3857), 'resolution': (1.1952623656738226, -1.1952623656793226)}, {'bbox': (12795252.428246655, 544843.4961954451, 12795405.42182946, 544996.4897782521), 'crs': CRS.from_epsg(3857), 'resolution': (1.1952623656738226, -1.1952623656793226)}, {'bbox': (12795405.421829462, 544843.4961954451, 12795558.415412268, 544996.4897782521), 'crs': CRS.from_epsg(3857), 'resolution': (1.1952623656738226, -1.1952623656793226)}, {'bbox': (12795558.415412268, 544843.4961954451, 12795711.408995073, 544996.4897782521), 'crs': CRS.from_epsg(3857), 'resolution': (1.1952623656738226, -1.1952623656793226)}, {'bbox': (12795711.408995075, 544843.4961954451, 12795864.40257788, 544996.4897782521), 'crs': CRS.from_epsg(3857), 'resolution': (1.1952623656738226, -1.1952623656793226)}, {'bbox': (12795864.40257788, 544843.4961954451, 12796017.396160686, 544996.4897782521), 'crs': CRS.from_epsg(3857), 'resolution': (1.1952623656738226, -1.1952623656793226)}, {'bbox': (12796017.396160688, 544843.4961954451, 12796170.389743494, 544996.4897782521), 'crs': CRS.from_epsg(3857), 'resolution': (1.1952623656738226, -1.1952623656793226)}, {'bbox': (12796170.389743494, 544843.4961954451, 12796323.3833263, 544996.4897782521), 'crs': CRS.from_epsg(3857), 'resolution': (1.1952623656738226, -1.1952623656793226)}, {'bbox': (12796323.383326301, 544843.4961954451, 12796476.376909107, 544996.4897782521), 'crs': CRS.from_epsg(3857), 'resolution': (1.1952623656738226, -1.1952623656793226)}]
The DataPipe is complete 🙌, let’s visualize the entire data pipeline graph.
torchdata.datapipes.utils.to_graph(dp=dp_collate)

Into a DataLoader 🏋️#
Loop over the DataPipe using torch.utils.data.DataLoader ⚙️!
dataloader = torch.utils.data.DataLoader2(dataset=dp_collate, batch_size=None)
for i, batch in enumerate(dataloader):
box, img, metadata = batch
print(f"Batch {i} - img: {img.shape}, box sizes: {[len(b) for b in box]}")
Batch 0 - img: torch.Size([10, 3, 128, 128]), box sizes: [0, 3, 1, 2, 1, 0, 0, 0, 0, 0]
Batch 1 - img: torch.Size([10, 3, 128, 128]), box sizes: [3, 6, 7, 9, 7, 0, 0, 0, 0, 0]
Batch 2 - img: torch.Size([10, 3, 128, 128]), box sizes: [3, 13, 8, 4, 1, 0, 0, 0, 0, 0]
Batch 3 - img: torch.Size([10, 3, 128, 128]), box sizes: [1, 4, 3, 4, 2, 2, 0, 0, 0, 0]
Batch 4 - img: torch.Size([10, 3, 128, 128]), box sizes: [0, 0, 1, 1, 4, 2, 0, 8, 3, 0]
Batch 5 - img: torch.Size([10, 3, 128, 128]), box sizes: [5, 27, 37, 43, 36, 38, 18, 1, 2, 0]
Batch 6 - img: torch.Size([10, 3, 128, 128]), box sizes: [15, 40, 28, 56, 32, 31, 36, 4, 0, 0]
Batch 7 - img: torch.Size([10, 3, 128, 128]), box sizes: [3, 3, 24, 33, 45, 49, 44, 2, 0, 0]
Batch 8 - img: torch.Size([10, 3, 128, 128]), box sizes: [0, 0, 3, 6, 1, 9, 14, 1, 0, 0]
Batch 9 - img: torch.Size([10, 3, 128, 128]), box sizes: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
There’s probably hundreds of models you can 🍜 feed this data into, from mmdetection’s 模型库 🐼 to torchvision’s Models and pre-trained weights). But are we out of the woods yet?
Georeference image boxes 📍#
To turn the model’s predicted bounding boxes in image space 🌌 back to geographic coordinates 🌐, you’ll need to use an affine transform. Assuming you’ve kept your 🏷️ metadata intact, here’s an example on how to do the georeferencing:
for batch in dataloader:
pred_boxes, images, metadata = batch
objs: list = []
for idx in range(0, len(images)):
left, bottom, right, top = metadata[idx]["bbox"]
crs = metadata[idx]["crs"]
x_res, y_res = metadata[idx]["resolution"]
gdf = gpd.GeoDataFrame(
geometry=[
shapely.affinity.affine_transform(
geom=shapely.geometry.box(*coords),
matrix=[x_res, 0, 0, y_res, left, top],
)
for coords in pred_boxes[idx]
],
crs=crs,
)
objs.append(gdf.to_crs(crs=crs))
geodataframe: gpd.GeoDataFrame = pd.concat(objs=objs, ignore_index=True)
geodataframe.set_crs(crs=crs, inplace=True)
break
geodataframe
| geometry | |
|---|---|
| 0 | POLYGON ((12795245.323 545027.959, 12795245.32... |
| 1 | POLYGON ((12795252.428 545028.185, 12795252.42... |
| 2 | POLYGON ((12795227.218 545027.685, 12795227.21... |
| 3 | POLYGON ((12795306.384 545029.400, 12795306.38... |
| 4 | POLYGON ((12795496.658 545045.087, 12795496.65... |
| 5 | POLYGON ((12795504.103 545037.782, 12795504.10... |
| 6 | POLYGON ((12795623.979 545002.809, 12795623.97... |
Back at square one, or are we?